
AI趣味实验室,塑造创新教学新体验。
本期,我们将为大家介绍NeurIPS 19论文《First Order Motion Model for Image Animation》中提到的「AI换脸视频」实现的创新方法。只需要一张源图片(包含一个主体)和一个驱动视频(包含一系列动作),就能够生成一段融合视频,轻松实现AI换脸。
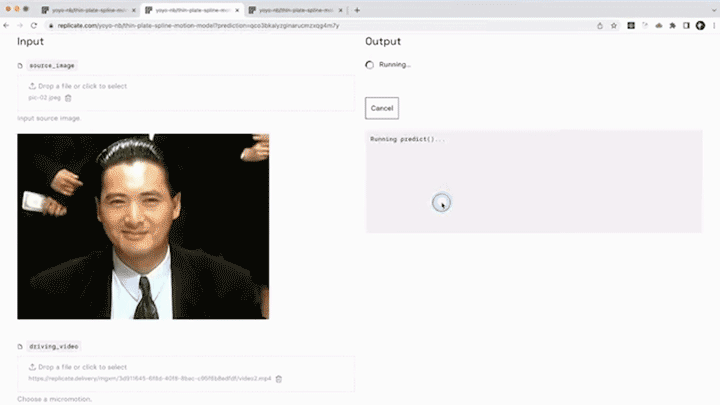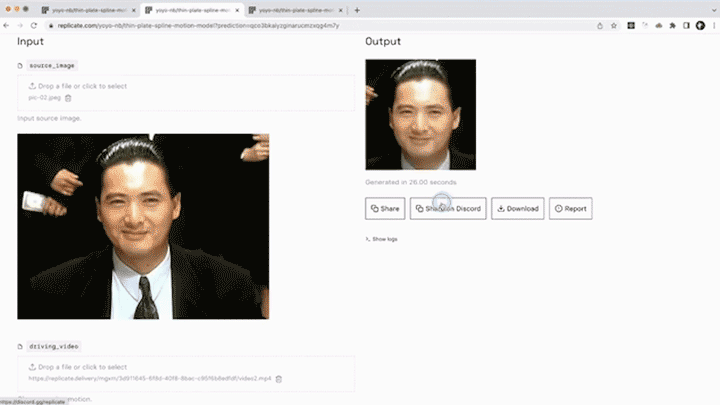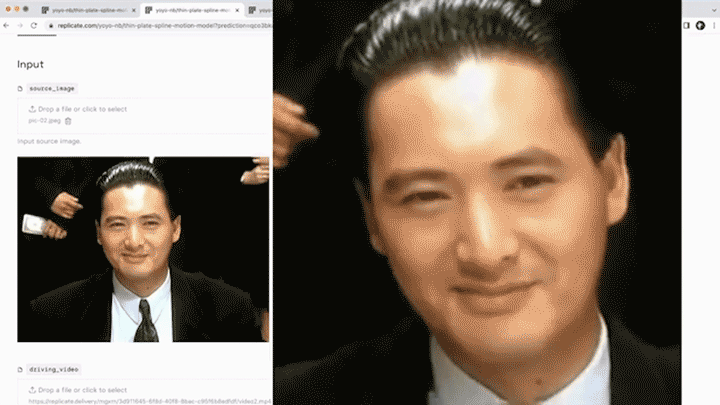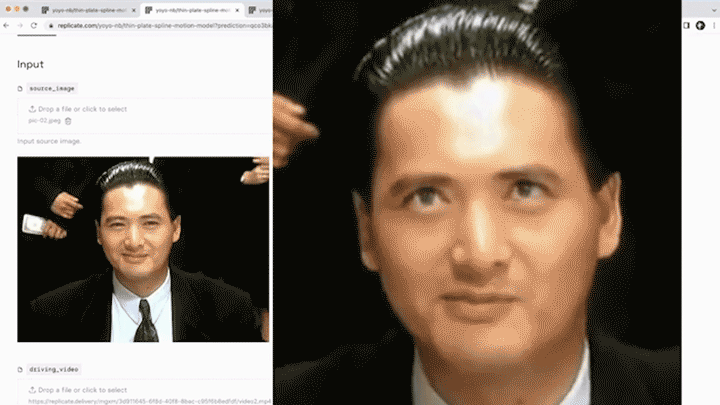
相信大家在浏览短视频平台时,已经领略过诸多趣味横生的恶搞表情视频,或是那些真假难辨的AI虚拟人物。随着换脸技术和表情迁移的科技浪潮席卷而来,人们开始热衷于利用卡通形象、动漫角色,甚至是真人照片,为自己打造另一个数字化的化身。
在传统意义上,换脸技术通常涉及对视频图像帧的精细操作,要求事先使用大量双方人脸图像数据进行训练,以实现源脸到目标脸的精确替换。然而,在视频会议这样的特定场景中,用户端往往只有有限的目标人脸数据,且没有足够的时间供我们去进行大量的数据训练。在这种情境下,换脸技术又是如何实现的呢?
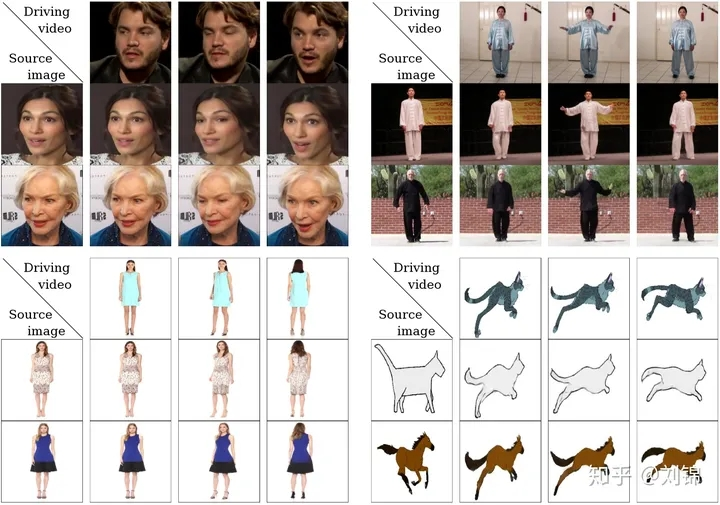
图源 | 知乎号:刘锦
以左上角的人脸表情迁移为例,给定一个源人物,给定一个驱动视频,可以生成一个视频,在这段视频中,主角是源图片中的人物,而动作和表情则完全来源于驱动视频。通常情况下,我们需要对源人物进行人脸关键点标注、进行表情迁移的模型训练。
但《First Order Motion Model for Image Animation》论文中提出的方法只需要在同类别物体的数据集上进行训练即可。比如实现太极动作迁移就用太极视频数据集进行训练,想要达到表情迁移的效果就使用人脸视频数据集voxceleb进行训练。训练好后,我们使用对应的预训练模型就可以达到前言中实时image animation的操作。
下面,我们通过一个有趣的案例来动手实验,尝试将女孩唱歌的动作迁移到冰墩墩上,从而实现冰墩墩唱歌的搞笑效果。



案例图示
本实验需要安装的包放置在requirements.txt这个文件中。执行以下命令进行批量安装。
In [1]:
!pip install -r requirements.txt
📌给视频添加音频
将一幅静态图片转化为一个动态视频。如果想让图片中的铁憨憨唱歌,还需要为生成后的视频添加音频内容。所以,编写如下两个功能函数。
In [2]:
import imageio
import torch
from tqdm import tqdm
from animate import normalize_kp
from demo import load_checkpoints
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from skimage import img_as_ubyte
from skimage.transform import resize
import cv2
import os
import argparse
import subprocess
import os
from PIL import Image
📌从视频中剥离出音频内容
In [3]:
def video2mp3(file_name):
“””
将视频转为音频
:param file_name: 传入视频文件的路径
:return:
“””
outfile_name = file_name.split(‘.’)[0] + ‘.mp3’
cmd = ‘ffmpeg -i ‘ + file_name + ‘ -f mp3 ‘ + outfile_name
subprocess.call(cmd, shell=True)
📌为一个视频添加音频内容
In [4]:
def video_add_mp3(file_name, mp3_file):
“””
视频添加音频
:param file_name: 传入视频文件的路径
:param mp3_file: 传入音频文件的路径
:return:
“””
outfile_name = file_name.split(‘.’)[0] + ‘-f.mp4’
subprocess.call(‘ffmpeg -i ‘ + file_name
+ ‘ -i ‘ + mp3_file + ‘ -strict -2 -f mp4 ‘
+ outfile_name, shell=True)
📌设置静态图片路径,读入图片,归一化到256*256大小
In [5]:
source_path = ‘Inputs/test.png’
source_image = imageio.imread(source_path)
source_image = resize(source_image,(256,256))[…, :3]
📌载入关键点检测模型,用于人脸关键点检测
In [6]:
checkpoint_path = ‘checkpoints/vox-cpk.pth.tar’
generator,kp_detector = load_checkpoints(config_path=’config/vox-256.yaml’,checkpoint_path=checkpoint_path)
📌读入.mp4文件
In [7]:
if not os.path.exists(‘output’):
os.mkdir(‘output’)
relative=True
adapt_movement_scale=True
cpu=False
video_path = ‘1.mp4’
if video_path:
cap = cv2.VideoCapture(video_path)
print(“[INFO] Loading video from the given path”)
else:
cap = cv2.VideoCapture(0)
print(“[INFO] Initializing front camera…”)
fps = cap.get(cv2.CAP_PROP_FPS)
size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
📌抽取mp4文件中的音频内容和视频内容
In [8]:
video2mp3(file_name = video_path)
fourcc = cv2.VideoWriter_fourcc(‘M’,’P’,’E’,’G’)
#out1 = cv2.VideoWriter(‘output/test.avi’, fourcc, fps, (256*3 , 256), True)
out1 = cv2.VideoWriter(‘output/test.mp4’, fourcc, fps, size, True)
📌读取视频的每一帧,进行人脸运动估计,对原图上进行人脸运动生成
先对视频中每一帧图像进行人脸关键点检测和人脸运动估计。然后在原输入图片上进行人脸运动恢复,并最终整合成视频输出。
In [9]:
cv2_source = cv2.cvtColor(source_image.astype(‘float32’),cv2.COLOR_BGR2RGB)
with torch.no_grad() :
predictions = []
source = torch.tensor(source_image[np.newaxis].astype(np.float32)).permute(0, 3, 1, 2)
if not cpu:
source = source.cuda()
kp_source = kp_detector(source)
count = 0
while(True):
ret, frame = cap.read()
frame = cv2.flip(frame,1)
if ret == True:
if not video_path:
x = 143
y = 87
w = 322
h = 322
frame = frame[y:y+h,x:x+w]
frame1 = resize(frame,(256,256))[…, :3]
if count == 0:
source_image1 = frame1
source1 = torch.tensor(source_image1[np.newaxis].astype(np.float32)).permute(0, 3, 1, 2)
kp_driving_initial = kp_detector(source1)
frame_test = torch.tensor(frame1[np.newaxis].astype(np.float32)).permute(0, 3, 1, 2)
driving_frame = frame_test
if not cpu:
driving_frame = driving_frame.cuda()
kp_driving = kp_detector(driving_frame)
kp_norm = normalize_kp(kp_source=kp_source,
kp_driving=kp_driving,
kp_driving_initial=kp_driving_initial,
use_relative_movement=relative,
use_relative_jacobian=relative,
adapt_movement_scale=adapt_movement_scale)
out = generator(source, kp_source=kp_source, kp_driving=kp_norm)
predictions.append(np.transpose(out[‘prediction’].data.cpu().numpy(), [0, 2, 3, 1])[0])
im = np.transpose(out[‘prediction’].data.cpu().numpy(), [0, 2, 3, 1])[0]
im = cv2.cvtColor(im,cv2.COLOR_RGB2BGR)
#joinedFrame = np.concatenate((cv2_source,im,frame1),axis=1)
#joinedFrame = np.concatenate((cv2_source,im,frame1),axis=1)
#cv2.imshow(‘Test’,joinedFrame)
#out1.write(img_as_ubyte(joinedFrame))
out1.write(img_as_ubyte(im))
count += 1
# if cv2.waitKey(20) & 0xFF == ord(‘q’):
# break
else:
break
cap.release()
out1.release()
cv2.destroyAllWindows()
📌将前面抽取出来的音频内容,整合到新生成的视频中
In [6]:
video_add_mp3(file_name=’output/test.mp4′, mp3_file=video_path.split(‘.’)[0] + ‘.mp3’)
待新的视频生成后,用播放器打开,就能体验效果啦!

当然,除了这个有趣的实验案例,青软还为想要拓展教学视野、获取丰富教学和实践资源的老师,提供更多课程、实验和项目试用机会,诚邀您来参与!


注:文章部分内容及图片来源自网络,仅供学习参考,如有侵权请联系删除。
![]()

✦ 往期回顾 ✦
> 正式上线!新疆大学与青软携手打造《数据库原理与技术(金仓KingbaseES版)》课程
> 促就业 | 青软助力「西安软件园-宝鸡文理学院春季校企宣讲会」圆满举办
> 青软与华为联合发布「产教融合解决方案」,以高质量人才培养支撑新质生产力发展
> 获评上榜!青软集团荣获「2023年度青岛市民营领军标杆企业」

本篇文章来源于微信公众号: QST青软集团